TrackNet
Deep Learning for High-Speed Tiny Object Tracking
TrackNet is a specialized deep learning architecture designed for tracking high-speed and tiny objects in broadcast sports videos. These objects (like tennis balls or shuttlecocks) are often small, blurry, and occasionally invisible due to high shutter speeds and motion.
Problem Statement
| Feature | TrackNet Strategy |
|---|---|
| Small Object | Heatmap-based detection over pixel-level coordinates |
| Motion Blur | Learning patterns from consecutive frames (Temporal Information) |
| Visibility | Regression of (x, y) even when the ball is partially occluded |
Architecture Core
The network is trained not only to recognize the ball from a single frame but also to learn flying patterns from consecutive frames, utilizing spatiotemporal features.
TrackNet vs. TSM (Temporal Shift Module)
The design philosophy differs significantly based on the task goal:
- TrackNet: Goal is to estimate instantaneous velocity . This is a regression task requiring precise spatial coordinates.
- TSM: Goal is to classify actions . This is a classification task over a temporal window where local pixel precision is less critical.
Comparison Matrix
| Feature | TrackNet | TSM |
|---|---|---|
| Task Aim | ||
| Loss Function | ||
| Input Focus | Local spatial features + Temporal | Global temporal context |
Evolution
TrackNetV1 (AVSS 2019)
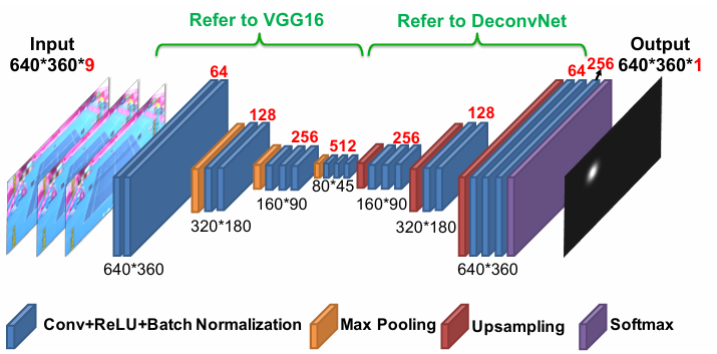
- Input:
- Output: heatmap.
- Method: VGG-based Encoder-Decoder. Binary heatmap with Circle Hough transform.
TrackNetV2 (ICPAI 2020)
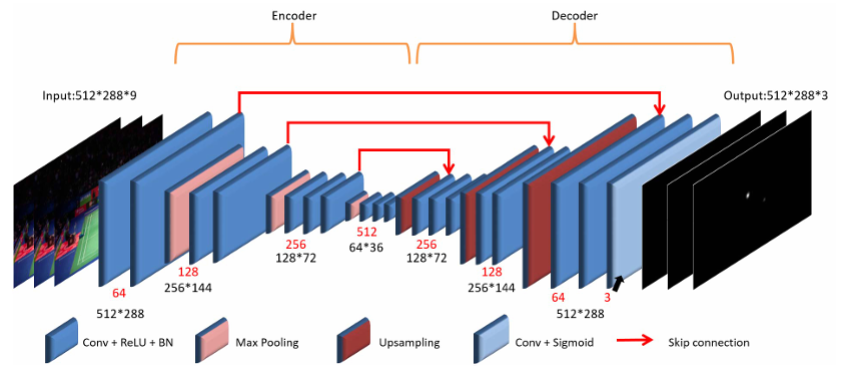
Key improvements over V1:
- U-Net Skip Connections: Replaced VGG encoder-decoder to reduce False Positives and trajectory jitter.
- Multi-Frame Output: Output changed from to for smoother trajectory prediction.
- Soft Gaussian Heatmap: Replaced hard binary labels with smoother Gaussian heatmaps (Soft labels) to handle motion blur.
TrackNetV3
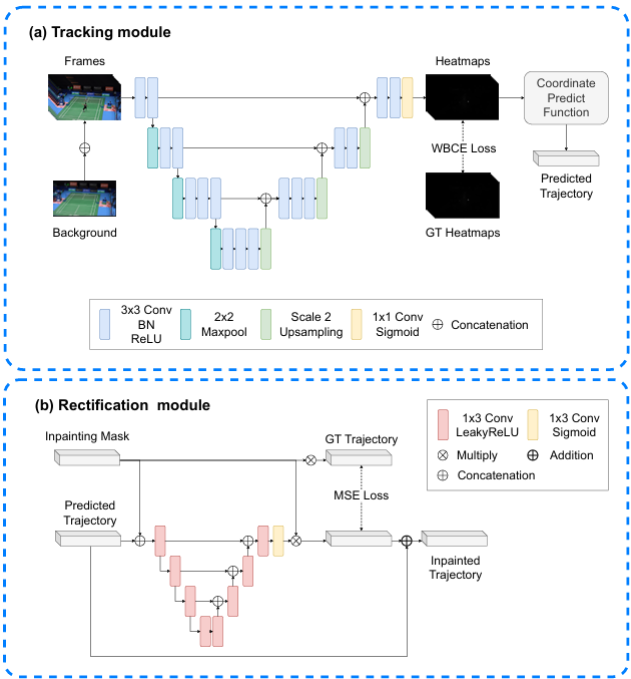
- Background Integration: Added background image as input for better differentiation.
- Mixup Training: Applied Mixup data augmentation.
- Rectification Module: Introduced a module to rectify track misalignment during occlusions or overlapping.
Performance Assumption
TrackNetV3 significantly outperforms V2 in scenarios with heavy occlusions, but requires background frames for optimal initialization.